
Most college mathematics or computer science departments have a "crank bin": a box with collected papers that people have sent in for review. There are all sorts of gems in there: a two-page proof of the Riemann hypothesis, a drawing that demonstrates P = NP, and of course, a draft of a patent application for a free energy machine. Many professors just throw this crap out, but some collect it because it makes for a good read when you're feeling discouraged by a hard problem.
Me, whenever I need a pick me up, I go read some of the latest new techniques for SEO. There are a handful of fundamentals about page design and other nitty things like URL structure that are generally accepted as good SEO, and you can derive all of this from the principles of not completely failing at web design. Non-brain-damaged web design and link building are 100% of SEO.
Anyone who tells you different is a quack that is only trying to separate you from your money.
Quackery in medicine is pretty easy to spot, and quackery in computing is pretty similar:
- "Research" performed by people with slim technical backgrounds
- Suspect experimental controls or no experimental controls
- Little investigation of alternative explanations for phenomena
- Little to no data reported from findings
Let's look at my favorite example: SEOMoz. It's a wealth of collected information about SEO, almost completely anecdotal, and of course you can get access to more "professional" information for a fee. There probably a place on the site where you can buy Acai berries, but I haven't found it yet.
SEOMoz recently published a correlation analysis of ranking factors for Google and Bing. First of all, out of all the factors they measured ranking correlation for, nothing was correlated above .35. In most science, correlations this low are not even worth publishing. As a warm-up, the author explains a graph that shows negative correlation with rank for URL length and .com TLD extension, meaning that longer URLs were less high up in the search results as were URLs that came from .com domains:
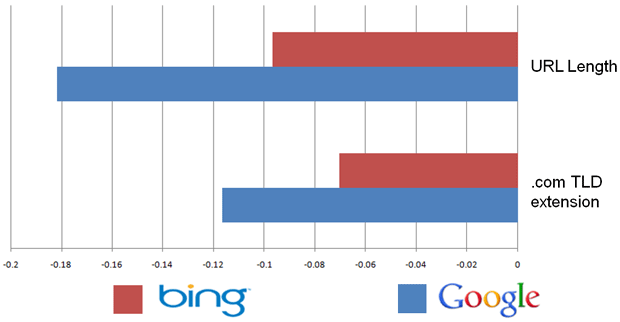
This is the explanation, verbatim:
The data for URL length shows that longer URLs are negatively correlated with ranking well. This isn't particularly shocking, and it probably iswise to limit the length of our URLs if we want to perform well in the engines. However, the second data point on .com TLD extensions shouldn't necessarily suggest that using .com as your top-level domain extension will actually negatively affect your rankings, but merely that all other things being equal, .com domains didn't perform as well in the dataset we observed as other domain extensions.
That is not how science works. You can't discount data just because you feel like it. Also notice that the most negative correlation metric they found was -.18. A correlation of zero suggests that the two variables are completely independent of one another. Such a small correlation on such a small data set, again, is not even worth publishing.
There is no hypothesis being tested here. It's just graphs, and misleading graphs at that. The sad part is, SEOMoz is as close as the SEO industry comes to real science. They may be presenting specious results in hopes of looking like they know what they're talking about, but at least they are collecting some sort of data.
Everything else in the field is either anecdotal hocus-pocus or a decree from Matt Cutts. When you hire an SEO consultant, what you are really paying for is domain experience in the not-failing-at-web-design field. It's fine to pay for this kind of service, but beware of anyone who claims to have studied the effects of different techniques. They might give you skin failure.
Update: It looks like I am not the first one to notice this. Here is a good article with more statistical formalism on SEOMoz quackery.